Merkle Trees
What is a Merkle Tree?
A Merkle tree, also known as a hash tree, is a data structure that is used to efficiently verify the integrity of a large amount of data. It is a tree-like structure in which each leaf node contains the hash of a data block, and each non-leaf node contains the hash of its child nodes. The root node of the tree is called the Merkle root, and it is a hash of all of the leaf nodes.
The Merkle root is a hash of all of the data blocks in the tree. This means that if any of the data blocks are changed, the Merkle root will also change. This can be used to verify the integrity of the data in the Merkle Tree.
To verify the integrity of the data in a Merkle tree, you can calculate the hash of each data block and compare it to the hash that is stored in the tree. If the hashes match, then the data has not been tampered with.
Merkle trees are used in a variety of applications, including:
Blockchains: Merkle trees are used to verify the authenticity of transactions in blockchains. For example, in Bitcoin, each block of transactions is hashed together to create a Merkle root. This Merkle root is then included in the block header of the next block, and so on. This way, it is possible to verify that all of the transactions in a blockchain have not been tampered with.
Distributed systems: Merkle trees can be used to verify the integrity of data in distributed systems. For example, if a file is stored on multiple servers, a Merkle tree can be used to create a hash of the file that can be used to verify that the file is the same on all of the servers.
File verification: Merkle trees can be used to verify the integrity of files. For example, if you download a file from the internet, you can use a Merkle tree to verify that the file has not been tampered with.
Here is a visual representation of a Merkle Tree that is representing User balances at an exchange:
![Merkle-tree-structure-JP[1][1].jpg](https://images.squarespace-cdn.com/content/v1/6486ddc4fb42f33c24a2bac9/1694597231805-8CGK407JHMQ59JA15QWV/Merkle-tree-structure-JP%5B1%5D%5B1%5D.jpg)
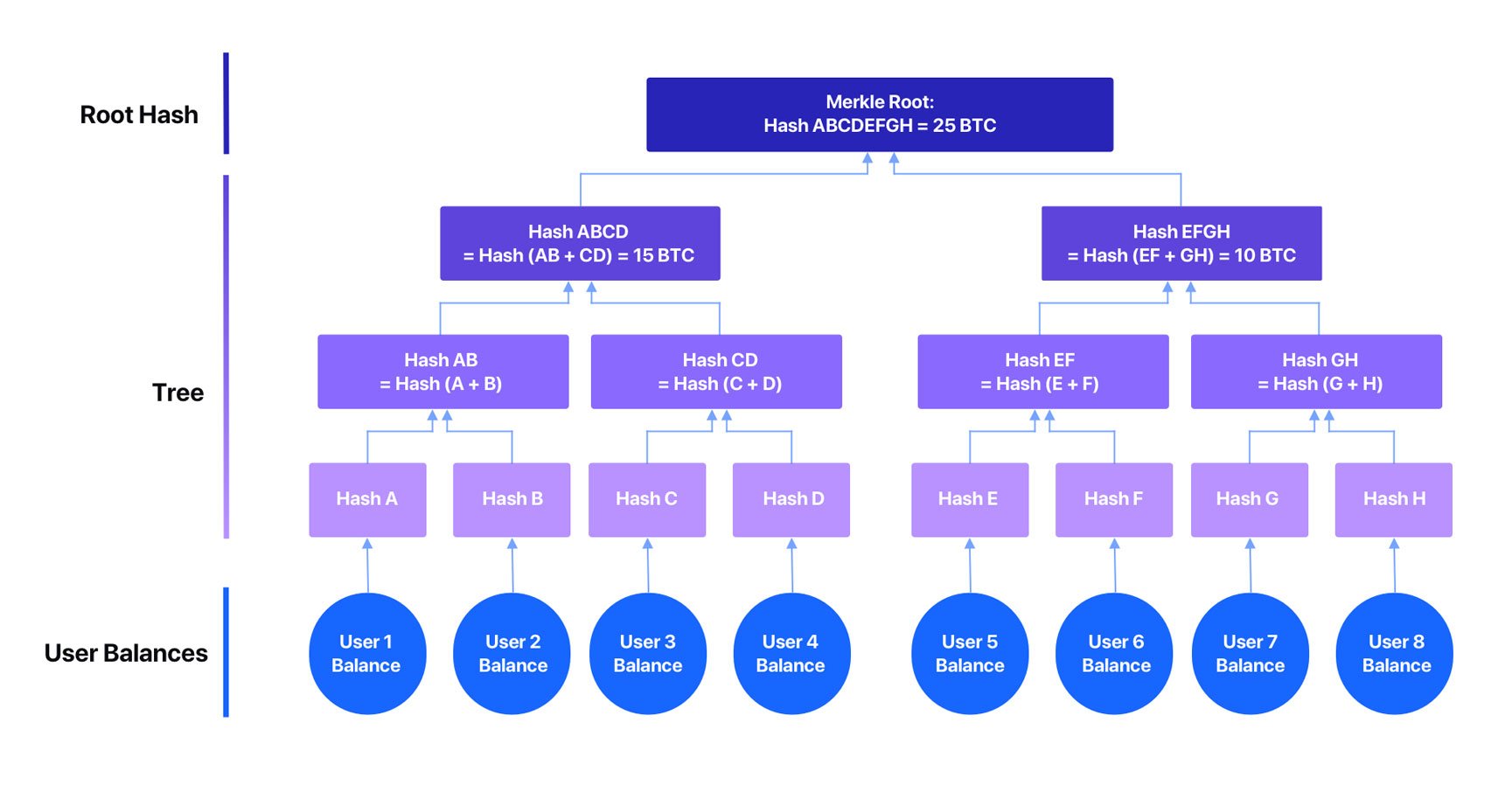
The Merkle Tree method creates individual “leaves” that represent each data subset, where each “leaf” has a hash that represents the information contained in it. When we gather several “leaf” data subsets, we can build a data “branch,” and this “branch” is also represented by its hash, created by combining all “leaf” hashes into a new single fixed-size hash value. By gathering all “branch” hashes, we can create the final “tree” hash, which as a result gives us the final Merkle Root Hash that represents all the content contained in our complete data structure.
This process is very efficient, because only the hashes of the blocks need to be calculated, not the entire file. This makes it possible to verify the integrity of large files quickly and easily.
Why are Merkle Trees relevant?
Merkle trees are a powerful tool for verifying the integrity of data. They are efficient, scalable, and secure. As a result, they are used in a variety of applications where it is important to ensure that data is not tampered with - in our case the Proof of Solvency. Each user can verify that your data leaf i.e. account balance “exists” in the Merkle Tree and that none of the leafs in the Merkle Tree have been altered.